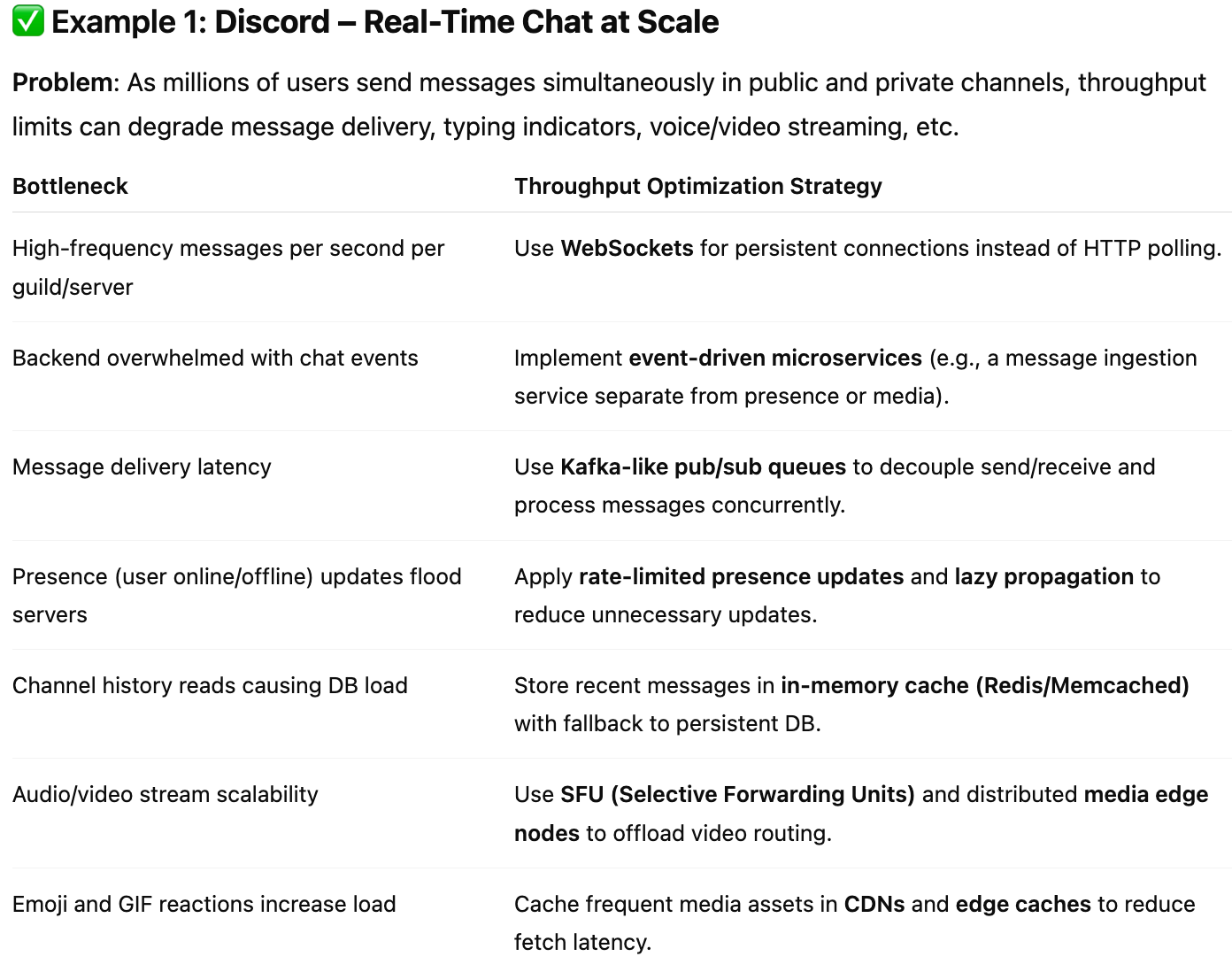
🚀 Throughput in System Design
The Unsung Hero of Performance

When building scalable systems, engineers often prioritize latency, availability, and reliability. But another essential performance pillar—throughput—is sometimes overlooked.
Throughput is not just a backend buzzword. It’s the difference between a system that gracefully handles a flash sale, and one that crashes during it. Between a smooth ride-hailing experience and a frustrating timeout when booking a cab.
This post dives deep into what throughput is, why it matters, how it differs from latency, and how to improve it in real-world systems.
What Is Throughput?
Throughput measures how much work your system can handle over a period of time.
In system design, throughput is usually measured as:
Transactions per second (TPS) – Financial systems or databases
Requests per second (RPS) – Web servers or APIs
Messages per second – Messaging systems like Kafka or RabbitMQ
Jobs processed per minute/hour – Background task systems like Celery or AWS Lambda
Analogy: Think of a factory production line.
Latency is the time it takes to make one product.
Throughput is how many products you can make per hour.
Throughput vs. Latency: Why the Difference Matters
Many confuse throughput with latency, but they are distinct and often trade off with each other.

You can have high throughput with high latency (e.g., batch processing).
You can have low latency with low throughput (e.g., quick single-threaded tasks).
In real-time systems (like chat apps), latency matters more. In bulk processing (like data pipelines), throughput is king.
Factors That Impact Throughput
Throughput is affected by a complex interplay of hardware, software, and architectural decisions. Below are some of them:
1. Resource Constraints (CPU, Memory, Disk, Network)
CPU-bound systems (e.g., video encoding, ML inference) will hit throughput ceilings unless CPU is optimized or parallelized.
Memory pressure can trigger GC (garbage collection) or OOM (out-of-memory) errors.
Disk I/O bottlenecks appear in systems that rely on heavy file reads/writes or logging.
Network saturation becomes a limiting factor in high-traffic APIs or streaming platforms.
2. Threading and Parallelism
Limited thread pools or use of synchronous (blocking) code reduces concurrency.
Poorly designed parallelism (e.g., excessive context switching) can degrade performance.
Not using async/non-blocking I/O where appropriate (like Node.js, async Python, or reactive Java) leads to underutilization of system resources.
3. Database and Storage Limits
Limited read/write throughput in traditional RDBMS unless scaled vertically or sharded.
High write contention on indexes or foreign keys.
Slow query performance due to missing indexes or complex joins.
Storage backends like S3 or file systems may throttle throughput under high concurrency.
4. Serialization and Deserialization Overhead
JSON, XML, or Protobuf parsing can consume CPU and delay processing.
Poorly designed data models (large payloads, deeply nested structures) slow down request handling.
5. Inefficient Algorithms
Suboptimal time/space complexity can drag down performance at scale.
Example: O(n²) sorting logic inside an endpoint can crash under load.
6. Third-Party Dependencies
External APIs can limit throughput with rate limits or latency.
Payment gateways, SMS/email providers, or authentication services can become bottlenecks.
7. Request Size and Payloads
Larger payloads take longer to transmit and process.
Systems with frequent large file uploads/downloads see degraded throughput if not optimized via chunking or streaming.
How to Improve Throughput
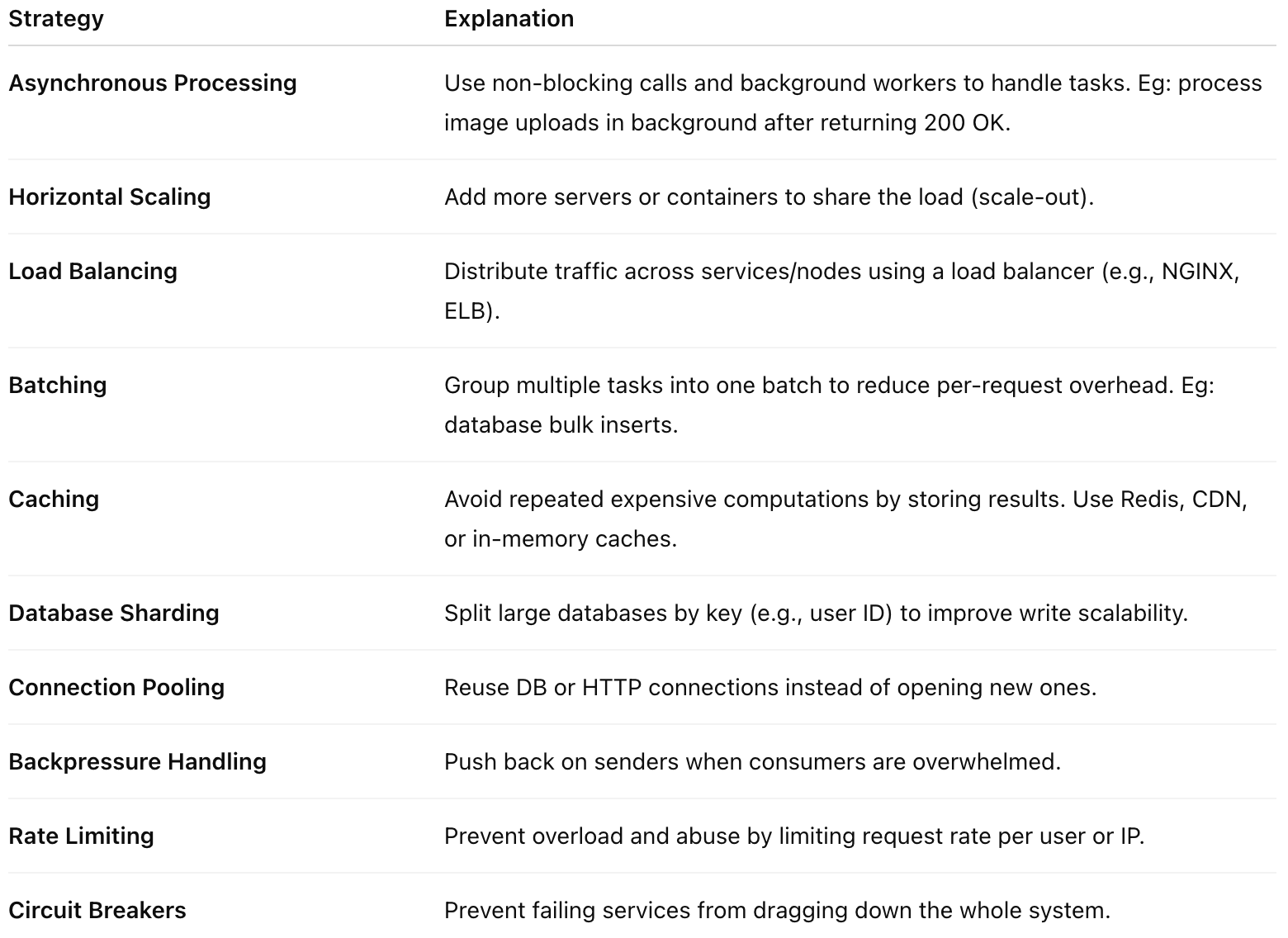
Practical Examples