
Availability in System Design
Building Resilient Systems

In the world of system design, availability is one of the most fundamental pillars—often discussed, frequently misunderstood, and critically important. Whether you’re building a simple web app or a planet-scale distributed system, availability determines whether your users can access your service when they need it.
This article unpacks availability from first principles: what it is, how to measure it, why it’s critical, what causes downtime, and how to approach designing for it.
What Is System Availability?
Availability = the fraction of time your system is able to successfully serve requests:
Formula:
Availability = (Uptime/(Uptime + Downtime)) * 100
If a system is expected to run for 1000 hours and it's unavailable for 1 hour, its availability is
Availability = (999/1000)*100 = 99.9%
It's NOT:
The same as reliability (which measures correctness and failure frequency)
The same as performance (which measures speed or responsiveness)
A measure of durability (which refers to data safety)
The “Nines” of Availability
High-availability systems are often described using “nines”—representing the percentage of time a system is up.

Each extra nine adds significant cost and engineering complexity. That’s why setting realistic targets aligned with business goals is crucial.
Why Availability Matters
Revenue Impact: For platforms like Amazon or Netflix, even 10 minutes of downtime translates to millions in lost sales.
User Trust: Users expect apps to be available 24/7. Downtime erodes brand credibility.
SLA Violations: Many companies offer service-level agreements (SLAs) with penalties for unmet availability targets.
Regulatory Compliance: In industries like finance and healthcare, availability isn’t just good practice—it’s required by law.
Availability is not just a technical metric—it's a business-critical promise.
What Causes Downtime?
Downtime is any period when a system is not operational or is unable to perform its intended function. Understanding the causes helps us design systems that can withstand or gracefully recover from failure. Let’s break down the common causes in more depth:
1. Hardware Failures
Physical components such as servers, storage drives, power units, or network switches can fail due to age, overheating, manufacturing defects, or power issues.
Example: A disk failure in a single server can lead to data loss if redundancy (e.g., RAID) is not implemented.
Mitigation: Use hardware redundancy (e.g., RAID, multiple network interfaces), health checks, and automated replacement mechanisms in cloud platforms.
2. Software Bugs
Uncaught exceptions, memory leaks, deadlocks, or deployment errors can bring down services.
Example: A bad deployment that crashes the authentication service could block users from logging in.
Mitigation: Use staging environments, blue-green deployments, canary releases, and automated rollback systems.
3. Network Issues
Failures in the network stack — whether in data centers, between regions, or in DNS resolution — can prevent access even if services are running fine.
Example: A DNS misconfiguration can make your service unreachable even though all servers are up.
Mitigation: Design with multi-region failover, redundant DNS providers, and internal monitoring of public endpoints.
4. External Dependencies
Microservices or third-party services (e.g., payment gateways, SMS providers, CDN) may go down.
Example: If your system depends on a payment gateway, and it experiences downtime, users cannot check out.
Mitigation: Implement circuit breakers, fallback strategies, graceful degradation, and redundant vendors.
5. Configuration Errors
Manual or automated config changes can lead to incorrect service behavior.
Example: Updating a load balancer rule that routes all traffic to a dead backend.
Mitigation: Use infrastructure-as-code, version control, peer reviews, and automated config validation.
6. Capacity Overload
A sudden spike in traffic (real or malicious) can overwhelm the system and cause it to crash.
Example: A flash sale or an unexpected viral event brings more traffic than the system was designed to handle.
Mitigation: Use auto-scaling, rate limiting, load shedding, and DDoS protection.
How to Design for High Availability
Designing for high availability (HA) is about building resilient systems that minimize downtime and recover quickly from failure.
1. Redundancy at Every Layer
Design for redundancy at the compute, storage, and network layers.
Horizontal Scaling: Run multiple instances of services behind a load balancer.
Multi-AZ and Multi-Region: Use multiple availability zones and, when necessary, multiple geographic regions.
Storage Redundancy: Use replicated databases (e.g., primary-replica setups) and durable object storage (e.g., S3 with replication).
2. Automatic Failover Mechanisms
Failover means automatically shifting traffic or functionality to a standby system if the primary one fails.
Databases: Use managed databases like AWS RDS with automated failover between primary and replica.
DNS: Use failover-aware DNS systems (e.g., Route 53 health checks).
Traffic Routing: Tools like Envoy, Istio, or AWS ALB/NLB support traffic redirection during partial failure.
3. Graceful Degradation
Design systems so that when part of the system fails, the rest continues to function.
Example: If your recommendation engine is down, serve cached recommendations instead of showing an error.
Benefit: Users perceive better reliability even during partial outages.
4. Health Checks and Self-Healing
Use periodic health checks to monitor system components and replace unhealthy ones automatically.
Containerized Apps: Kubernetes automatically restarts failed pods.
Cloud Instances: Auto-recovery policies can reboot or recreate failed VMs.
5. Observability and Alerting
You can’t fix what you can’t see. Availability depends on early detection.
Monitoring: Use Prometheus, Grafana, CloudWatch, Datadog
Alerting: Set up SLAs/SLIs and automatic alerts on latency, errors, and availability
Logging: Centralized logs (e.g., ELK, Loki) for root cause analysis
6. Traffic Management and Load Balancing
Even distribution of traffic and intelligent routing during spikes or outages is essential.
Global Load Balancers: Use geo-based routing or latency-based routing.
Rate Limiting & Throttling: Prevent any single user or service from overwhelming the system.
Practical Examples

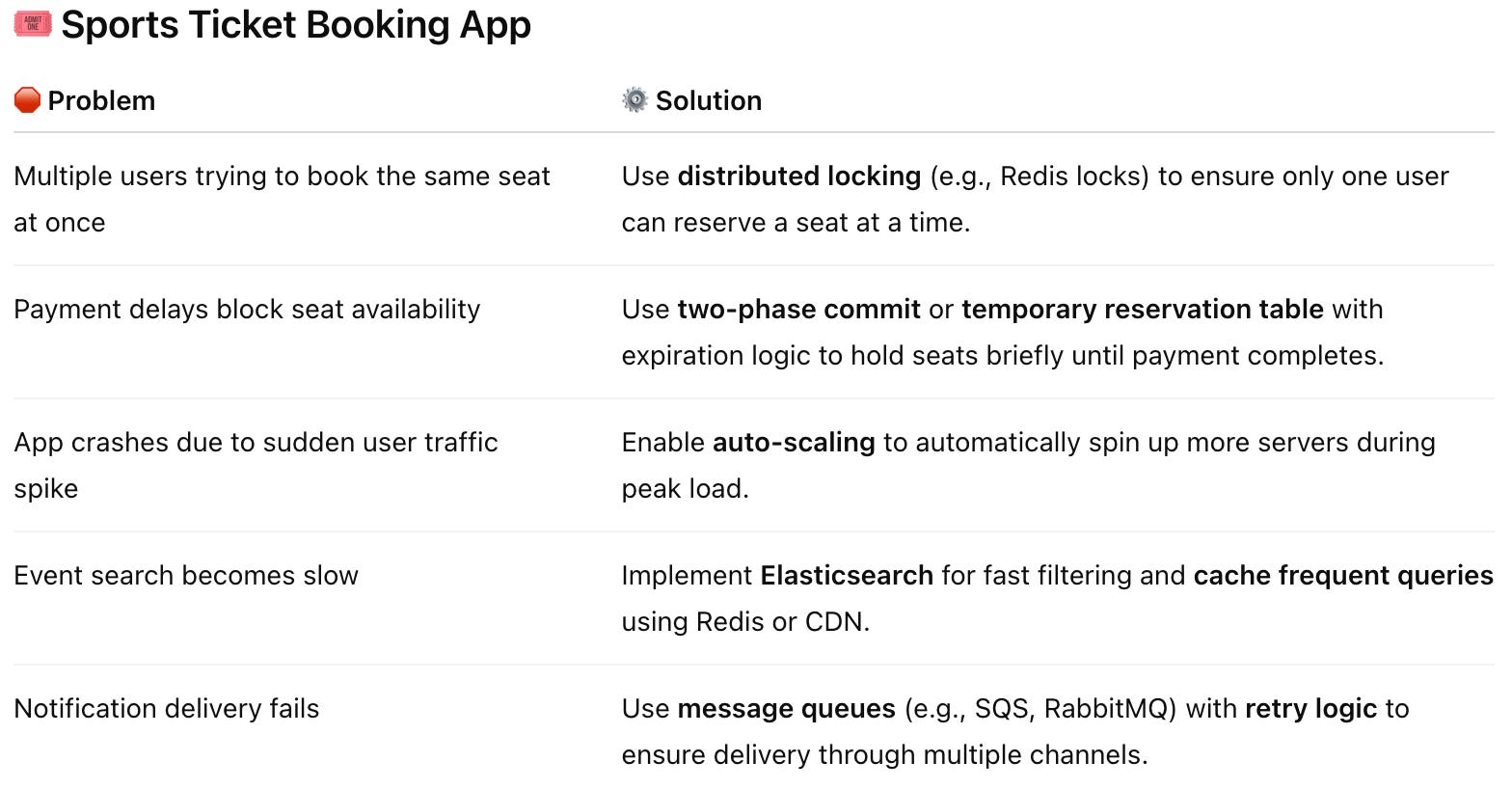

Cheat sheet for improving the system availbility
